话务量预测一直是政务热线职场运营中的核心问题,它对于现场排班安排和人员招聘培训都具有前瞻性影响,可为现场运营提供数据指导和参考依据,尤其对于应对疫情反复、政策变化或其他应急状况下的话务量突增状况可提供及时预警,提高突发事件的处置能力和日常状况下的运营效率。
但与此同时这也是一个难点问题:话务量受到业务、政策生命周期,季节变动,极端天气,节假日等诸多综合因素的复合影响,预测模型的选择和应用较为复杂。
近年来随着“接诉即办”工作的深入开展,各地政务服务类热线因其受理范围宽泛、业务复杂、群众期望值逐年增高等因素,话务量逐年大幅提升,受疫情政策等不可控因素影响的比例逐渐加大,因此传统的自上而下根据外部业务政策发展趋势进行外推话务预测的方式已不再适用。如何从现有海量历史话务数据挖掘入手,构建基于业务量的时间序列格式化数据,运用合适的统计学模型进行数据内生关系的挖掘和分析,进行自下而上的趋势内推和预测工作成为了当下的可行之策。
通过对某政务热线近一年来的话务数据进行复盘,发现不同时段影响话务的因素重多,其中包括天气情况、政策发布、突发事件等因素(图1)。
(一)天气情况
恶劣天气:雾霾、雷雨大风、大冰雹、暴雪、强降雨等,尤其是进入汛期以来,关于城市低洼地区出现积水等诉求明显增多。
(二)政策发布
各级政府关于疫情管控或其他政策的发布和调整一般对话务量有较为明显的滞后性影响。
(三)突发事件
突发事件一般会大幅影响当日话务量,随着时间影响程度递减。
(四)时段性
1、当日分时:每日的上午9-10时,下午的15-16时会呈现明显的呼入量波峰,之后呼叫量会逐步降低。
2、特殊季节:如在七、八、九月份的电力迎峰度夏、十一月至次年三月的供暖季,有关电力和供暖的诉求明显增多。
3、节假日:一般来说工作日呼叫量会较节假日呼叫量增高,经统计工作日呼叫量比非工作日平均高31.5%左右。

图1:部分影响话务量的原始数据样例(未清洗)
综上,影响话务量因素众多,各因素呈现周期性、分散性、复杂性特点:不同时间段有不同的影响因素,各因素间权重并不在一个维度,不太可能通过传统的线性模型去拟合分析。另外各方因素交织在一起共同发挥作用,很难判定某一因素能够在长周期内持续起主导性影响作用,各因素之间的内生关系并不显现,因此需要专业的机器学习模型通过统计计算发掘。
随机森林(Random Forest)作为有代表的一种集成学习类机器学习算法,对于解决海量数据环境下的分类和回归问题有着良好的应用效果。
核心思想是将许多棵决策树(Decision Tree)整合成森林并用来预测最终结果:他用随机放回的抽样的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下回归预测,最后将所有决策树的输出值取均值即为最终结果。
随机森林算法得到的每一棵树都是很弱的,但是大家组合起来就很厉害了。可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家投票得到结果。而这正是群体智慧(swarm intelligence),也就是经济学上说的“看不见的手”在起着预测作用。
其对于呼叫中心话务量预测的场景适用性如下:
1.海量数据分析适用。随机森林中需要分若干弱决策树,能够有效地运行在大数据集上。政务热线多年的运营经验积累下海量的话务和业务数据,样本越大,决策树就可分的越多,不同决策树所覆盖评价角度就越广,得到的最终结果就更准确;
2.复杂影响因素适用。刚才提到,影响话务量因素众多且权重不同,而决策树因其投票机制使其先天能够能够处理具有高维特征的输入样本,不需要降维处理。而且对于政策、重大事件空白日而默认的缺省值问题也能够获得很好的处理结果;
3.便于归因分析适用。随机森林预测方式本质上是基于决策树,在生成过程中,能够获取到内部生成误差的一种无偏估计,从而评估各个特征在回归问题上的重要性,便于解释影响当前影响话务量的因素。
python中的sklearn包对随机森林模型做了很好的封装。我们用其对原始数据进行清洗,模型的训练与评估(图2)。
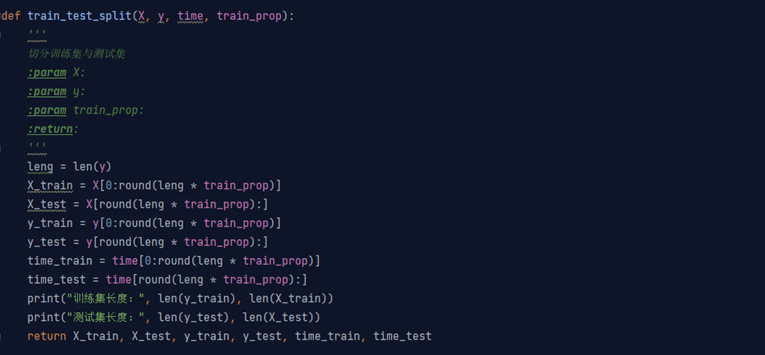
图2:模型训练过程中的代码(部分)
此外我们将随机森林预测法和其他常用的话务预测模型,如上期值预测、ARIMA、移动加权回归预测、或其他组合模型进行了对比,结果显示随机森林模型在政务热线话务量预测应用上效果最好(图3)。
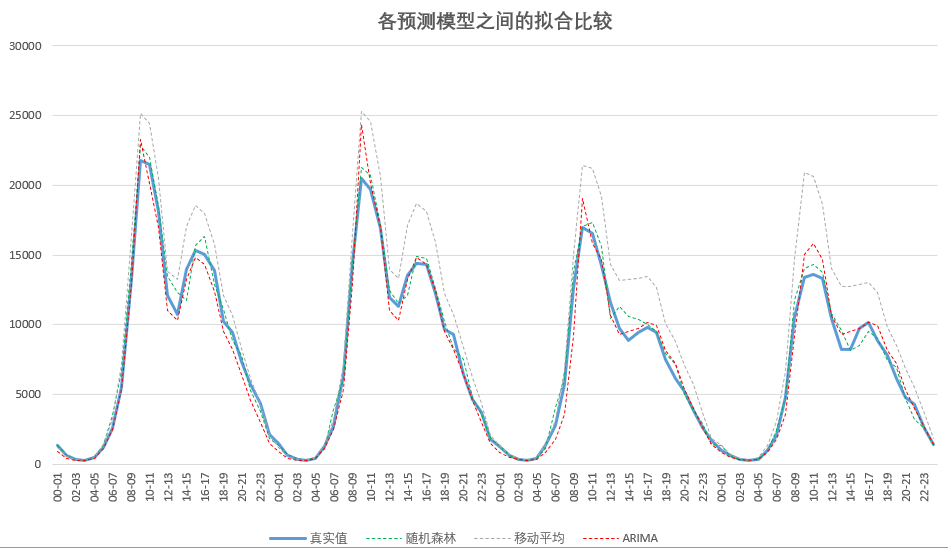
图3:模型之间的拟合比较
经过对某周四至周日(工作日和休息日各两天)数据进行数据拟合对比,随机森林预测值与实际数值误差率为9%,移动平均误差率23.9%,ARIMA误差率12.3%。
近年来各级接诉即办单位对于有效搭建数据平台、加强问题研判、发掘数据规律、提升感知能力和治理预见性有着迫切的需求。该成果作为已知的国内首例政务热线大数据话务量预测系统,阶段性成效得到了客户领导和运营团队的支持和肯定。下一步将持续进行数据源的丰富与模型参数调优,丰富展示效果,同时加强对影响因素的归因分析,不断进行系统的迭代升级。